과자를 먹으며 유튜브를 보는데 키보드에 손을 대기 싫다면?
손이 묻어있거나, 거동이 불편해서 키보드/마우스에 손대기 어렵다면?
Gesto는 웹캠 하나로 손동작을 인식해 PPT, YouTube, 게임을 조작할 수 있는 딥러닝 PC 제어 프레임워크입니다.
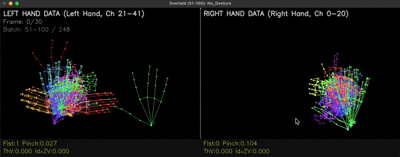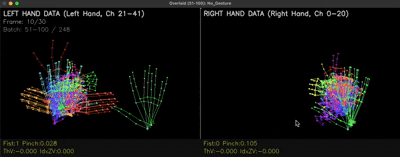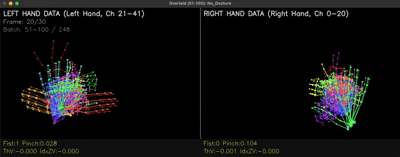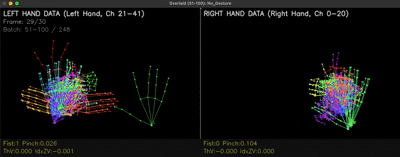
MediaPipe로 양손 관절 42개를 실시간 추출하고, LSTM으로 손동작의 시계열 패턴을 분류합니다. 새 제스처를 직접 학습시켜 plug-in 할 수 있는 확장형 구조로 설계했습니다.
발표 중에 무의식적으로 손이 올라갈 때마다 슬라이드가 넘어가면 곤란하잖아요. 그래서 동작 감지의 시작과 종료를 posture로 명시적으로 제어하는 안전장치를 두었습니다.
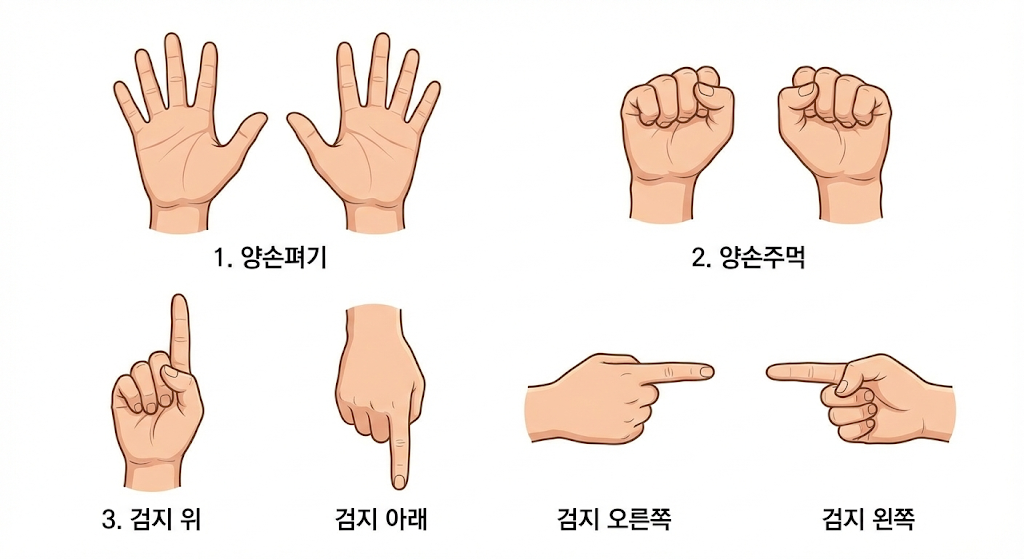
- 시작 — 양 손바닥을 2초간 보여주기
- 종료 — 양 주먹을 2초간 보여주기

| 동작 | 제스처 |
|---|---|
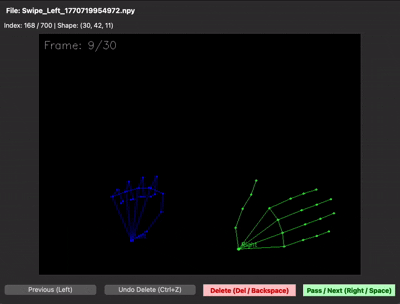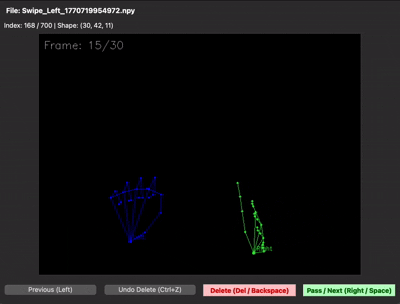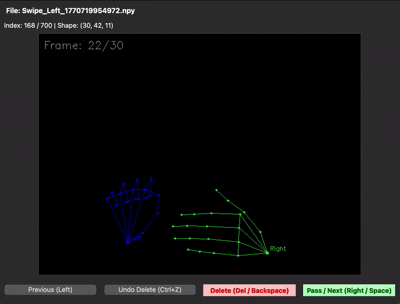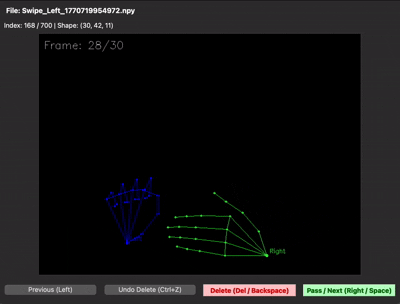
| 다음 슬라이드 | Swipe Left (왼손 주먹 + 오른손 왼쪽 스와이프) |
| 이전 슬라이드 | Swipe Right (오른손 주먹 + 왼손 오른쪽 스와이프) |
| 최소화 | Pinch In (한손 주먹 + 다른 손 pinch in) |
| 최대화 | Pinch Out (한손 주먹 + 다른 손 pinch out) |
| 동작 | 제스처 |
|---|---|
| 앞으로 5초 | Swipe Left |
| 뒤로 5초 | Swipe Right |
| 최소화 / 최대화 | Pinch In / Pinch Out |
| 재생 / 정지 | Play (한손 주먹 + 다른손 클릭) |

- 검지와 중지로 V자 2초간 유지
- 해제 시 거꾸로된 V자로 2초간 유지
확장성을 보여주기 위해 미로 게임도 만들었습니다. 한쪽 손가락 posture로 좌/우 회전, 다른 손가락 posture로 직진/후진을 동시에 제어합니다. PPT/YouTube처럼 클릭 단위 제어가 아니라, 연속적인 입력을 보낼 수 있다는 걸 보여주는 데모입니다.
한 손만 보고 판단하게 두면, 일상적인 손짓도 죄다 트리거로 잡혀버립니다. 그래서 양손이 모두 MediaPipe에 잡혀 있고, 그중 한 손이 주먹을 쥐고 있을 때만 gesture로 판별하도록 제약을 걸었습니다.
| 동작감지 X | 동작감지 O |
|---|---|
 |  |
| 분류 | 기술 |
|---|---|
| 모델 | LSTM (Tensorflow/Keras) |
| 관절 인식 | MediaPipe Hands (21 landmarks × 2hands) |
| GUI | PyQt5 |
| 키 입력 | Pynput |
| 데이터 | .npy (자체 수집 프레임워크) |
| 언어 | Python |
처음엔 "손동작 인식"을 그냥 손 모양 분류 정도로 단순하게 봤습니다. 그런데 개발을 시작하니, 정지된 손 모양(posture)과 움직이는 손 모양(gesture)은 본질적으로 다른 문제라는 걸 알게 됐습니다.
- posture — 정지된 동작. 시간과 상관없이 동작이 항상 같음. MediaPipe 관절 위치 계산만으로 인식 가능
- gesture — 움직이는 동작. 시간에 따라 동작이 달라짐. 이전 동작 데이터와 현재 데이터를 모두 고려해야 하는 시계열 데이터(sequential data) 이므로 RNN(순환 신경망)을 사용해야 함
그래서 둘을 같은 파이프라인으로 묶지 않고, posture는 좌표 계산으로 가볍게 처리하고 gesture는 LSTM에 맡기는 식으로 분리했습니다.
1차 관문은 손의 관절을 정확하게 뽑아내는 것이었습니다. 직접 모델을 학습시킬 수도 있었지만, 구글이 만든 MediaPipe가 손 관절을 21개로 세분화해서 x, y, z 좌표로 반환해주기 때문에 이걸 그대로 활용하기로 했습니다.

좌표가 정확하게 나오니까 posture는 별도 모델 없이 처리가 가능했습니다. 예를 들어 손펴기는 "네 손가락 TIP이 MCP보다 위에 있는가? (open_count ≥ 4) + MCP가 WRIST보다 위에 있는가?" 같은 단순한 좌표 비교로 끝납니다. 주먹은 그 반대로 open_count == 0, 거기에 중간 관절(PIP)이 끝(TIP)보다 위에 있어야 "확실히 쥔 주먹"으로 인정합니다.
MediaPipe가 실제로 양손 관절 21개를 어떻게 실시간으로 추적하는지 보면 이렇습니다.
결국 posture는 좌표 비교 몇 줄로 끝났고, 개발 비용을 전부 gesture 쪽에 집중할 수 있었습니다.
문제는 gesture였습니다. posture는 한 프레임의 좌표만 봐도 답이 나오는데, gesture는 "지금 이 순간"만 봐서는 알 수 없거든요. "그 직전까지의 움직임"이 함께 있어야 swipe인지 pinch인지 구분이 됩니다. 결국 시계열을 다룰 수 있는 신경망이 필요했고, RNN 계열을 들여다봤습니다.
그중에서도 LSTM(Long Short-Term Memory) 을 골랐습니다. 일반 RNN은 시퀀스가 조금만 길어져도 vanishing gradient 문제로 앞쪽 정보가 희석돼버리는데, LSTM은 셀(cell) 상태와 게이트(gate) 메커니즘으로 이걸 해결합니다. 30프레임짜리 짧은 시퀀스라도 처음 손이 어디서 출발했는지를 끝까지 기억하고 있어야 했기 때문에, LSTM이 적절했습니다.
시퀀스(시간 순서가 있는 데이터)를 다루기 위한 신경망이다. 같은 가중치를 반복 사용하면서 이전 시점의 은닉 상태를 현재 입력과 함께 넣어, "과거 맥락"을 어느 정도 기억한다. 그래서 음성·텍스트·동작처럼 순서가 중요한 데이터에 쓰인다.
전체 흐름은 다음과 같습니다. 웹캠 영상이 MediaPipe로 들어가 21개 관절 좌표가 뽑히고, 30프레임만큼 버퍼에 쌓이면 시계열 데이터로 묶여서 LSTM 모델에 입력됩니다.
모델 구조를 정한 다음엔 데이터부터 모아야 했는데, 여기서 첫 난관이 있었습니다. 팀원마다 카메라와의 거리, 녹화 프레임이 다 달라서 같은 swipe 동작도 데이터로 보면 전혀 다른 모양으로 찍혔거든요. 발표에서 정리한 문제는 세 가지였습니다.
- 데이터 분포 불균형 — 일반화 성능 저하
- 데이터 수집의 표준성 부재 — 누가 어떻게 찍든 제각각
- 전처리 오버헤드 증가 — 다시 정렬하느라 시간 낭비
그래서 누가 녹화하든 30fps × 1초로 통일되도록 자체 수집 프레임워크를 따로 만들었습니다. 촬영 환경별 인식 편차를 줄이기 위해 GUI 안에 밝기·노출 조정 기능도 함께 넣었습니다.
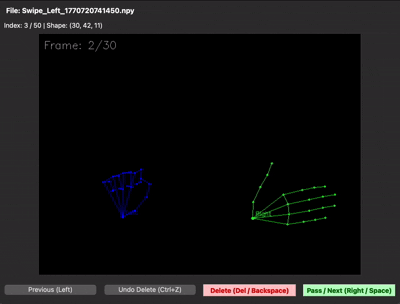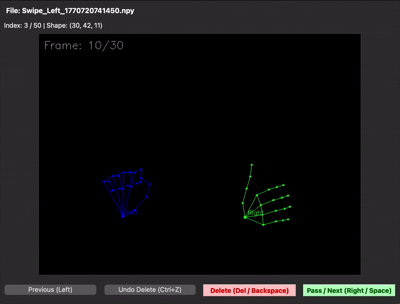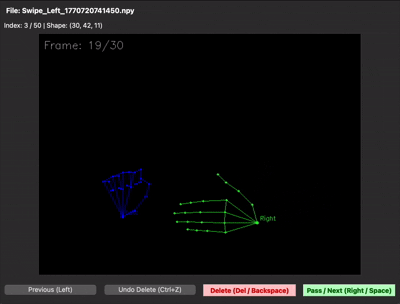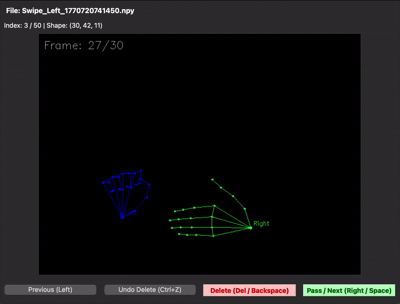
녹화본은 .npy 파일로 저장해 용량을 크게 줄였는데, 이번엔 바이너리라서 데이터가 제대로 들어갔는지 눈으로 확인이 안 됐습니다. 결국 .npy를 다시 시각화해주는 디버깅용 스크립트까지 함께 만들어서야 데이터 품질을 검증할 수 있었습니다.
| 데이터 수집 프레임워크 | npy 시각화 (디버깅 뷰어) |
|---|---|
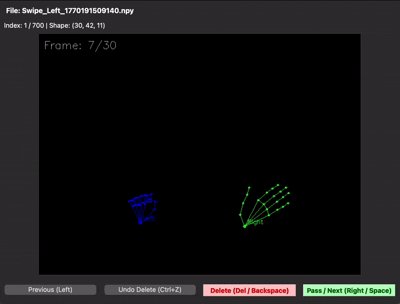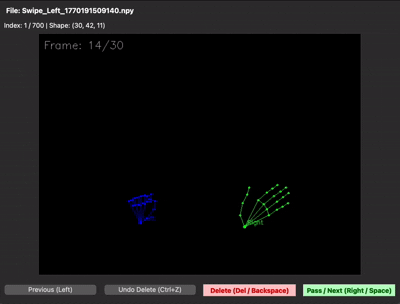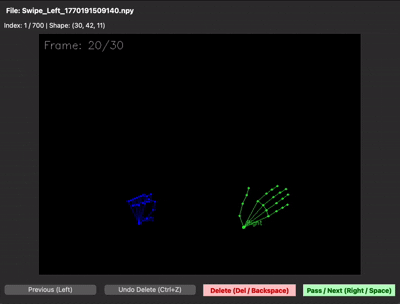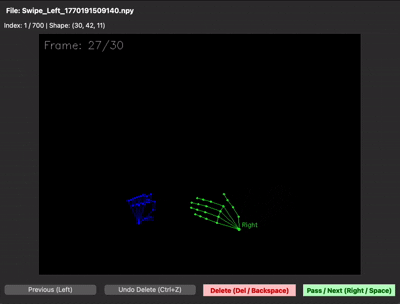 |
촬영자 입장에서도 헷갈리지 않도록 데이터 수집 매뉴얼을 별도 문서로 만들었습니다. 3대 핵심 수칙은 주먹 금지(주먹은 Wake-up 신호라서 데이터에 섞이면 안 됨), 다양하게(로봇처럼 똑같이 반복하면 모델 일반화가 무너짐), 시나리오 모드에서 본인 이름(id) 입력하기. 마지막 수칙이 나중에 결정적인 역할을 하게 됩니다.
.npy 한 샘플의 형태는 (30, 21, 3) — 30프레임, 21개 관절, 각 관절의 x/y/z 좌표였습니다. 영상 그대로 저장하는 것보다 바이너리 numpy 배열이 LSTM 입력으로 훨씬 효율적이었거든요.
모델은 Tensorflow로 구성했고, LSTM 두 층 사이에 Dropout을 끼우는 비교적 단순한 구조로 출발했습니다.
SEQUENCE_LENGTH = 30 # 1초 * 30fps
LANDMARKS_COUNT = 42 # 양손이라서 21 * 2
COORDS_COUNT = 3 # x, y, z
INPUT_SHAPE = (SEQUENCE_LENGTH, LANDMARKS_COUNT * COORDS_COUNT)
model = Sequential([
LSTM(128, return_sequences=True, input_shape=INPUT_SHAPE),
Dropout(0.2),
LSTM(64, return_sequences=False),
Dropout(0.2),
Dense(32, activation='relu'),
Dense(num_classes, activation='softmax')
])첫 학습 결과는 너무 깔끔했습니다. Accuracy는 1.0에 거의 닿고, Loss는 0에 거의 닿았거든요. "끝났다. 프로젝트 이렇게 쉬울 줄 몰랐다"라고 생각했죠.
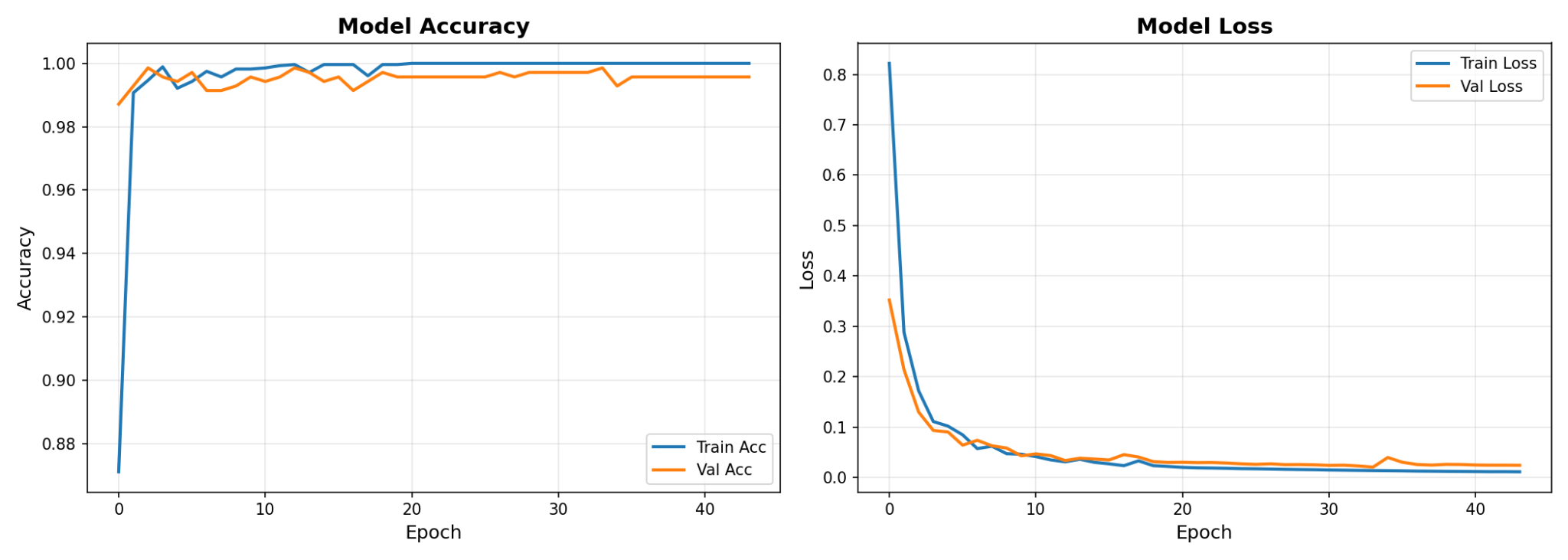
그런데 막상 GUI에 띄워서 인식 테스트를 해보니, 결과는 처참했습니다. Pinch In을 하면 Pinch Out이 잡히고, swipe도 멋대로 섞이는 식이었어요. Confusion matrix를 찍어보니 Pinch In ↔ Pinch Out 혼동이 어마어마했습니다.
좀 더 구체적으로 보려고, 강사님의 피드백을 받아 영상에 시간축 기준 클래스별 confidence를 같이 띄워봤습니다. 아래처럼 Swipe Left를 하고 있는데 Swipe Right와 Pinch In의 confidence가 동시에 튀어오르는 걸 발견했죠.
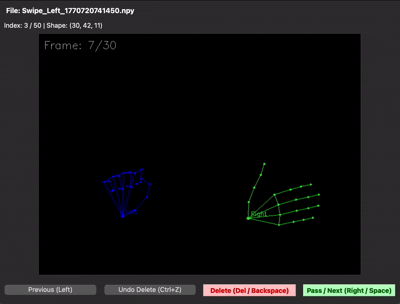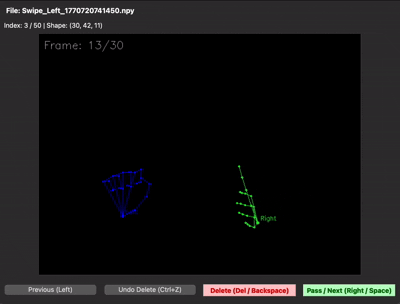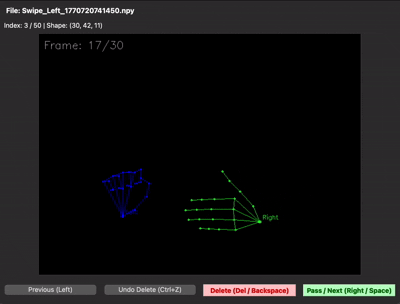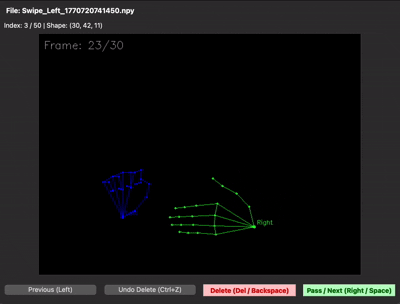
원인을 찾으려고 .npy 시각화 스크립트로 모든 샘플을 한 번에 겹쳐서 그려봤습니다. 그랬더니 다른 손들과 전혀 다른 방향으로 혼자 움직이는 빨간 손 하나가 눈에 띄었어요.
| Swipe_Left — 샘플 오버레이 (정지) | Swipe_Left — 시간축 누적 (애니메이션) | Swipe_Right — 같은 문제 |
|---|---|---|
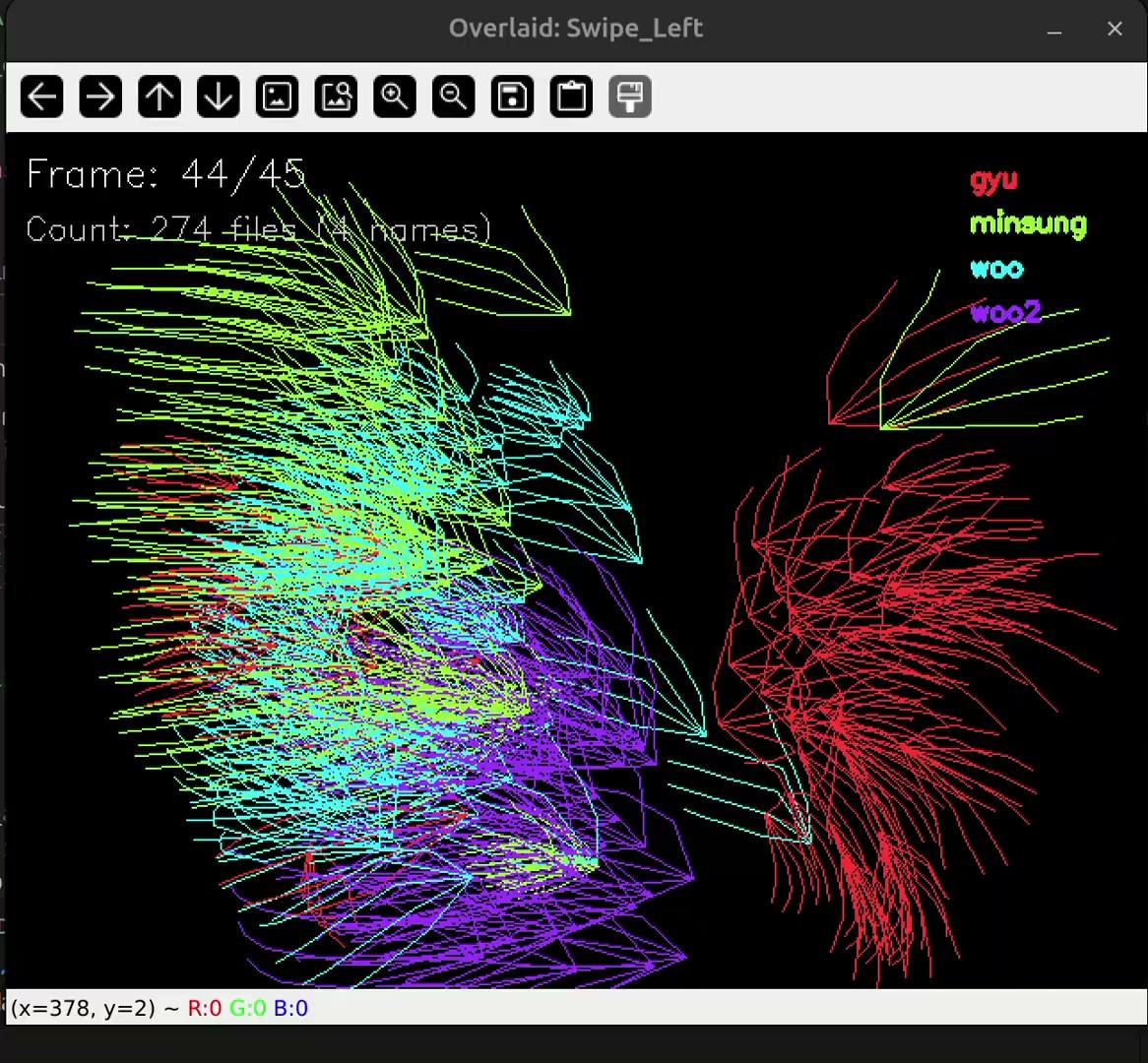 | 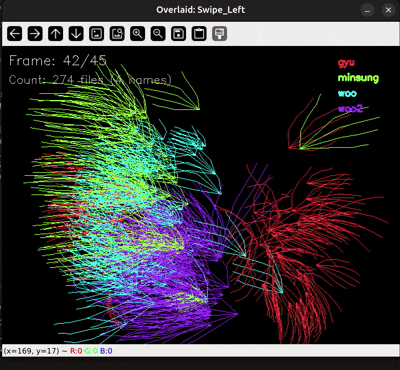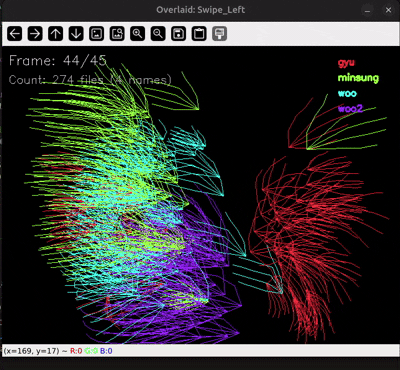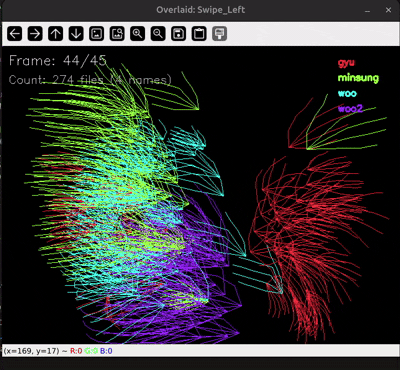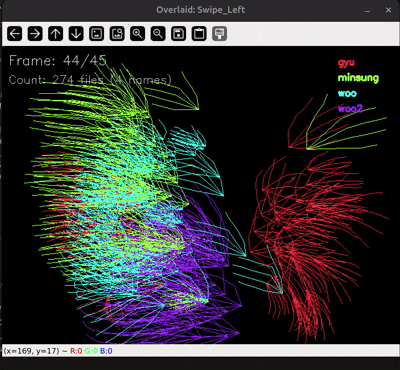 | 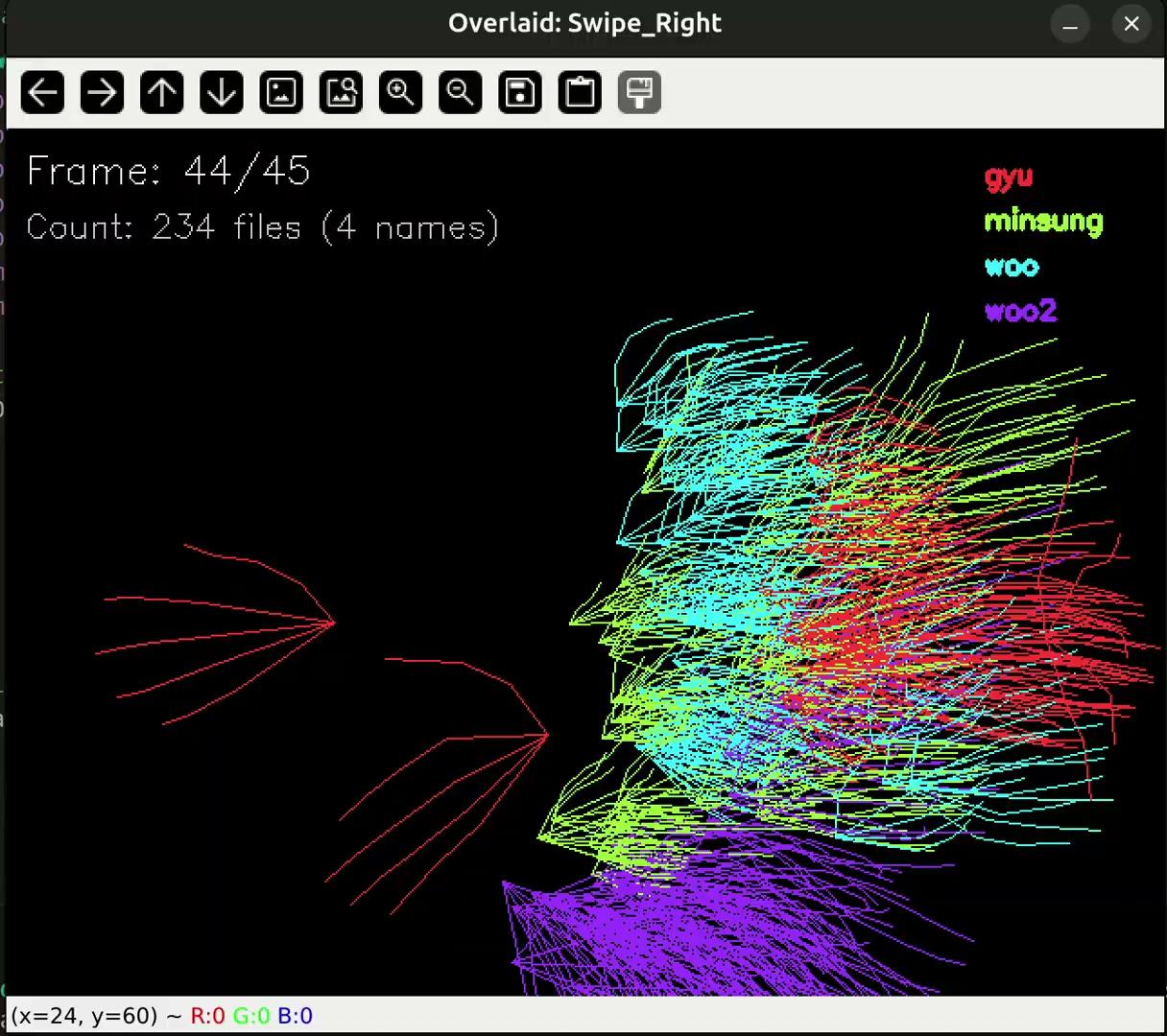 |
수집 가이드에는 "이렇게 갔다가 다시 돌아오지는 말자"라고 정해놨는데, 그 손은 혼자 정반대로 움직이고 있었습니다. 매뉴얼에 적어둔 "시나리오 모드에서 본인 이름(id) 입력하기"라는 수칙이 바로 여기서 빛을 발했습니다. 파일 메타데이터를 까보니 누가 만든 데이터인지 즉시 확인됐거든요. (이름은 ~~안~~ 가렸습니다 🤐)
그래서 데이터를 통째로 재수집했고, 결과적으로 총 6,276개의 샘플을 모았습니다. 이때 한 가지 더 정리한 게, 그동안 한 클래스에 왼손·오른손을 같이 학습시키던 걸 좌/우로 클래스를 분리한 거였습니다.
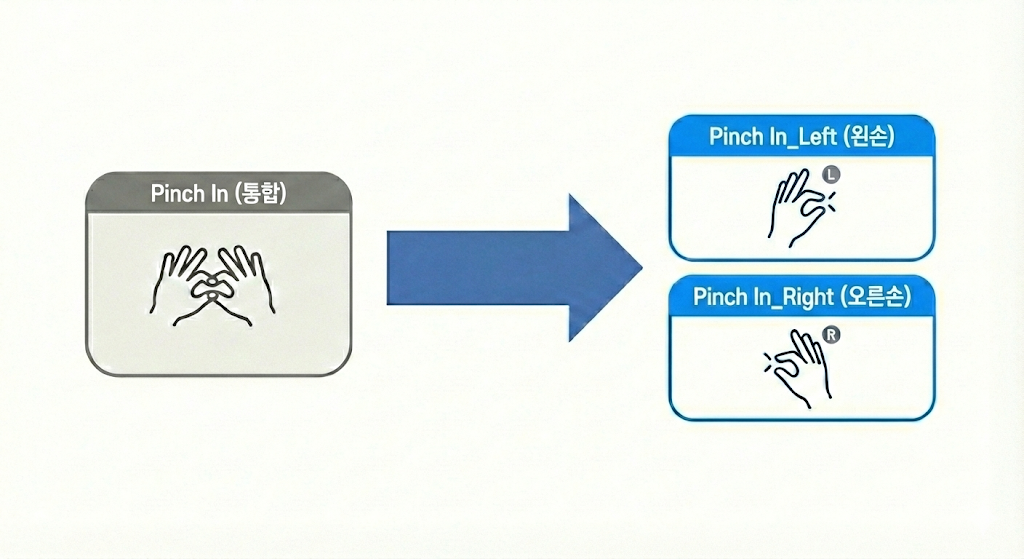
재수집·재학습 후에도 swipe right만 유독 점수가 안 나왔습니다. 데이터를 다시 들여다보니 두 가지 문제가 잡혔습니다.
30프레임을 제대로 못 채우는 문제 — 30프레임 중 처음 15프레임은 손이 거의 정지해 있고, 마지막 15프레임에서만 움직이는 샘플이 많았습니다. 그러면 LSTM이 "정지 상태도 swipe다"라고 학습해버립니다. 그래서 30프레임이 동작 전체를 꽉 채우도록 가이드를 다시 잡고 재녹화했습니다. npy 뷰어로 직접 샘플을 확인하면 그 차이가 한눈에 보입니다.
| 수집 초기 (동작이 절반 이하) | 재수집 후 (30프레임 꽉 채움) |
|---|---|
|  |
더해서 동작의 처음·끝만 모아놓은 No Gesture 클래스도 추가해 "지금은 아무 동작도 아니다"를 모델이 명확히 인식하게 했습니다. 아래는 No Gesture 샘플 데이터의 실제 분포입니다.
MediaPipe 인식 누락 프레임 — 손이 카메라와 수평이 되어 관절이 한 점에 몰리거나, 빠르게 움직일 때 순간적으로 좌표가 비거나 이상값으로 튀어버립니다. 그대로 두면 시퀀스 중간이 0으로 박혀서 LSTM이 흔들렸습니다. 비정상 프레임을 앞뒤 프레임 위치로 선형보간해 메우는 식으로 해결했습니다.
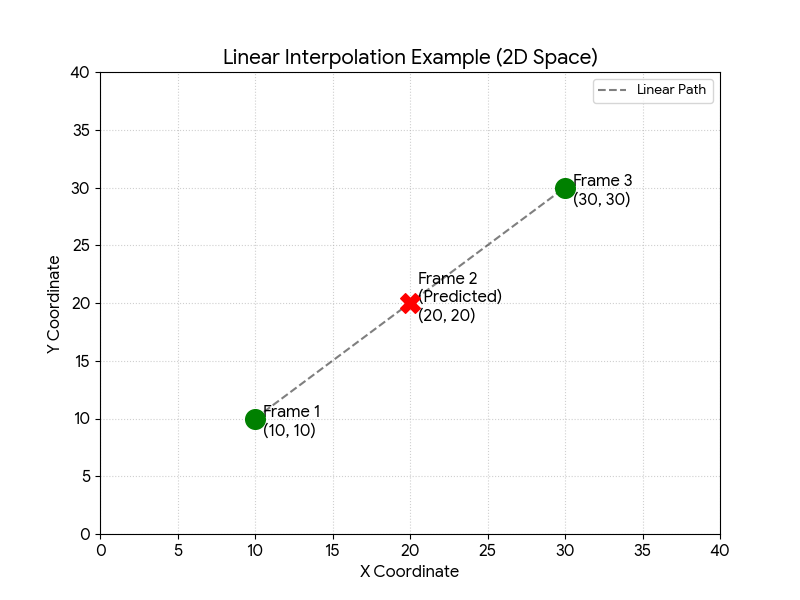
| 선형보간 전 (누락 프레임 존재) | 선형보간 후 (프레임 보완) |
|---|---|
 |  |
위의 수정으로 모델이 어느 정도 동작은 했지만, 이번엔 동작 간 간섭 문제가 남았습니다. Pinch가 Swipe로 잡히고, Play/Pause가 Swipe로 잡히는 식이었습니다. 원인을 짚어보니, 결국 좌표(x, y, z) 3채널만으로는 "손가락이 모이는 중인지" "검지가 앞으로 찌르는 중인지" 같은 동작의 의미를 모델이 충분히 구분하지 못하는 거였습니다.
그래서 좌표 3채널에 동작을 구분할 수 있는 보조 특징들을 직접 계산해 얹어 11채널(좌표 3 + 기하/운동 특징 8)로 확장했습니다. 손 한 쪽당 4개 — 주먹 여부, 엄지-검지 거리, 엄지 속도, 검지 Z 방향 속도 — 사람이 그 동작을 머리로 판별할 때 무의식적으로 보는 단서들을 그대로 채널로 추가한 셈입니다.
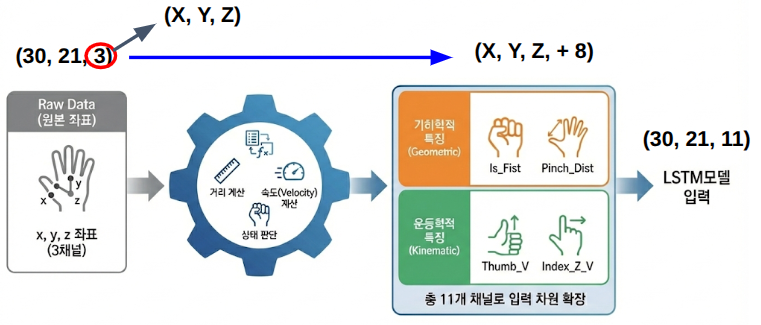
# 왼손 정보
new_data[i, :, 3] = left_feats[0] # Is_Fist: 주먹인지 아닌지
new_data[i, :, 4] = left_feats[1] # Pinch_Dist: 엄지와 검지 사이의 거리
new_data[i, :, 5] = left_feats[2] # Thumb_V: 엄지의 움직임 속도
new_data[i, :, 6] = left_feats[3] # Index_Z_V: 검지의 Z 방향 움직임 속도
# 오른손 정보
new_data[i, :, 7] = right_feats[0] # Is_Fist
new_data[i, :, 8] = right_feats[1] # Pinch_Dist
new_data[i, :, 9] = right_feats[2] # Thumb_V
new_data[i, :, 10] = right_feats[3] # Index_Z_V이게 효과가 있었던 이유를 좀 풀어서 말하면, 모델한테 힌트를 주는 셈입니다. 원래라면 LSTM이 학습 과정에서 "검지가 앞으로 빠르게 움직이는 게 swipe구나" 같은 패턴을 직접 알아내야 하는데, 우리가 그걸 미리 계산해서 "여기 이 채널을 중점적으로 봐"라고 알려주는 거죠. 결과적으로 학습 시간·비용은 줄고, 정합성은 올라갑니다.
이렇게 훈련한 결과 Pinch ↔ Swipe, Play ↔ Swipe 간섭이 사라졌습니다.
위 모든 수정(데이터 표준화, 좌/우 분리, 30프레임 활용, 선형보간, Feature Engineering, No Gesture 클래스)을 한 번에 한 게 아니라, 한 단계씩 적용하면서 LSTM 모델 버전을 lstm1 → lstm4까지 만들었습니다. 클래스별 F1 점수가 다음과 같이 점진적으로 올라갔습니다.
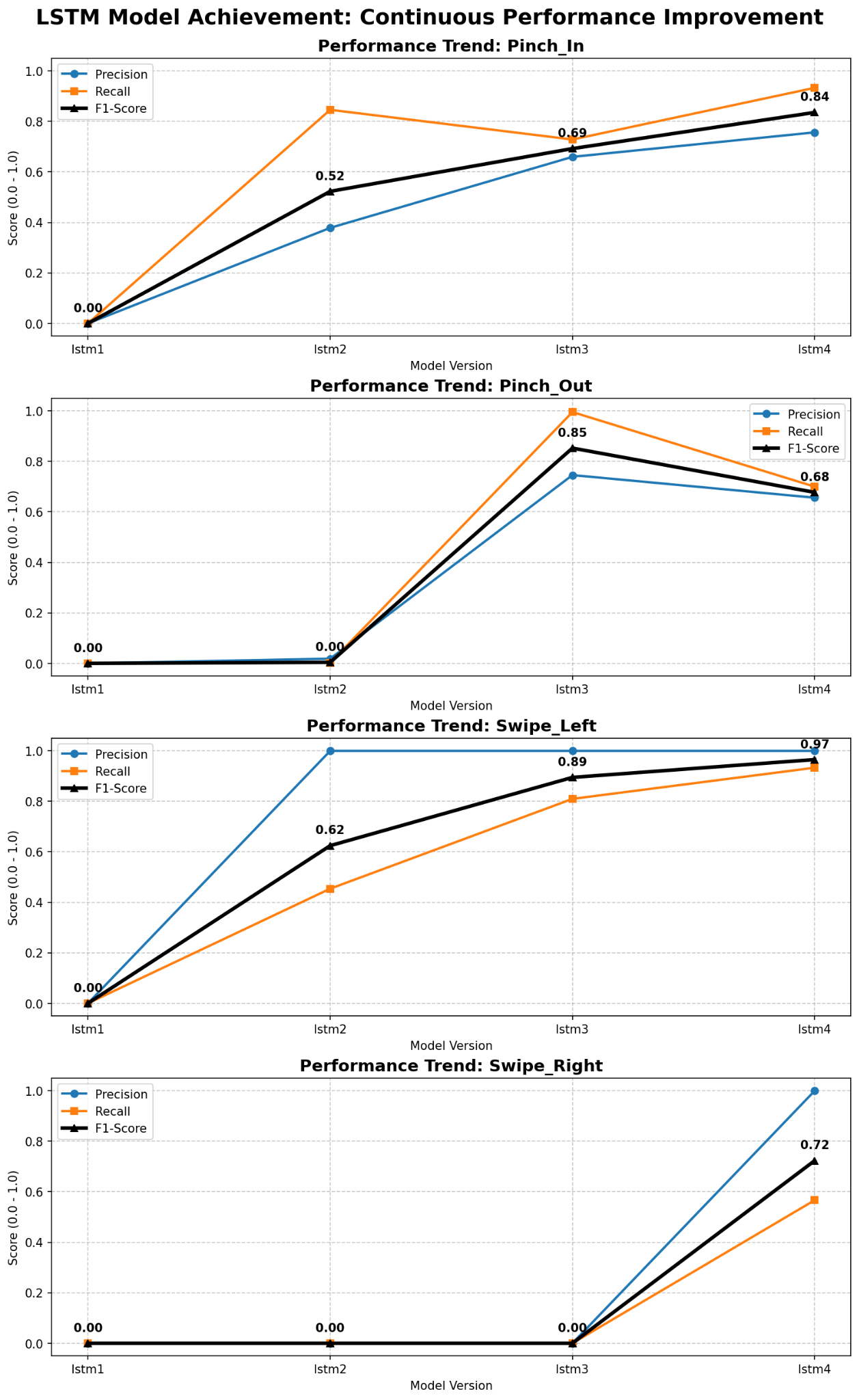
| 클래스 | lstm1 → lstm4 (F1) |
|---|---|
| Pinch_In | 0.00 → 0.52 → 0.69 → 0.84 |
| Pinch_Out | 0.00 → 0.00 → 0.85 → 0.68 |
| Swipe_Left | 0.00 → 0.62 → 0.89 |
| Swipe_Right | 0.00 → 0.00 → 0.00 → 0.72 |
특히 Swipe Right는 마지막까지 0점이었다가 11채널 + 좌/우 클래스 분리가 모두 들어간 lstm4에서야 비로소 살아났습니다. 인식률 평균 74% 라는 숫자는 이 모든 단계를 거쳐 나온 결과입니다.
최종 GUI 상에서는 아래처럼 인식 정확도가 실시간으로 표시되는데, 동작이 깔끔하게 들어오는 순간에는 99% 가까이 올라가는 걸 확인할 수 있었습니다.
- 데이터 시각화가 모델 디버깅을 살린다 — Accuracy/Loss 그래프만 봤으면 절대 못 찾았을 "빨간 손" 같은 라벨 노이즈가 시각화로 단번에 잡혔습니다. 모델 성능이 이상하면 모델보다 데이터를 의심해야 한다는 걸 체득했습니다.
- 메타데이터 한 줄의 가치 — 데이터 수집 매뉴얼에 "본인 이름(id) 입력하기"라는 한 줄을 넣어둔 게 결정적이었습니다. 추적 가능성은 처음부터 설계에 넣어야지 사후에 만들 수 없는 거였어요.(물론 범인을 찾기위해서)
- Feature Engineering = 모델에게 힌트 주기 — 좌표 3채널을 11채널로 늘리는 단순한 작업이 학습 시간을 줄이고 정확도를 끌어올렸습니다. 도메인 지식이 있다면 모델에 미리 떠먹여주는 게 무지성으로 깊은 네트워크에 맡기는 것보다 빠를 때가 있다는 걸 배웠습니다.
- 안 쓴 기술의 검증 결과 — YOLO는 "써보고 우리 시나리오엔 과한 것을 확인해서 뺐다"입니다.
초기 계획에는 사실 YOLO를 같이 쓰겠다고 적혀 있었습니다. 손이 작거나 멀리 있을 때 MediaPipe가 인식을 놓치는 게 걱정됐거든요. 그래서 YOLO로 손 영역만 bounding box로 잘라낸 뒤, 그 영역만 MediaPipe에 다시 넘기면 멀리 있는 손도 잘 잡을 거라고 봤습니다.
실험은 해봤습니다. 사용자가 멀리 갔을 때는 확실히 YOLO+MediaPipe 조합이 인식 정확도가 더 높았어요.
문제는 부작용이 컸다는 점입니다.
- 관절 인식이 떨림(질거림) — MediaPipe 단독은 굉장히 부드럽게 21개 관절을 따라가는데, YOLO bbox 안에서 한 번 더 MediaPipe를 돌리면 프레임마다 box가 미세하게 흔들리면서 관절도 떨립니다. 필터나 이동 평균으로 일부 완화는 가능했지만 깔끔하진 않았습니다.
- 사람 bbox 기반의 한계 — 처음 적용한 YOLO 모델은 사람을 잡아 bbox를 친 뒤, 그 안에서 손을 찾는 방식이었습니다. 그러다보니 손이 사람 bbox 밖으로 빠지면(손을 옆으로 쭉 뻗을 때 등) 관절이 통째로 깨져버렸습니다.
손만 따로 라벨링해서 손 전용 YOLO를 학습시키면 두 문제 모두 풀리긴 합니다. 다만 그 라벨링 작업 비용이 결코 작지 않았고, 무엇보다 우리 사용 시나리오에서 사용자가 카메라에서 멀리 떨어질 일이 거의 없었습니다. PPT/YouTube/게임 다 책상 앞에서 쓰는 거니까요.
그래서 "MediaPipe만으로 가다가, 정 안 되면 그때 YOLO를 붙이자"고 계획을 수정했고, 끝까지 그럴 일이 생기지 않아 YOLO는 빼게 됐습니다. 검토했지만 의식적으로 안 쓴 기술이라고 정리할 수 있겠네요.
| 이름 | 담당 |
|---|---|
| 송민규 | 프로젝트 리더, 데이터셋 검증, 모델 평가 담당 |
| 최민성 | Data Freamework 구축, Data 분석 및 시각화, QA, 발표 및 발표자료 |
| 이정우 | Data Framework 구축, QA GUI design 개선, 게임 제작 |
| 박우림 | 모델 학습 및 개선, 앱 구축, 데이터 수집 강화 훈련 |